Data Integrity












Data Integrity – A Journey, not a Destination
 The presentation will load below
The presentation will load below


Data Integrity has been on the agenda of regulatory authorities since the introduction of 21 CFR Part 11 in 19971. Before that the need to address data integrity issues was illustrated by ‘the generics scandal’ in the 1980s where falsified data was submitted to support drug approvals2.
1. Guidance for Industry Part 11, Electronic Records; Electronic Signatures — Scope and Application –http://www.fda.gov/downloads/RegulatoryInformation/Guidances/ucm125125.pdf
2. Joseph P. Reid, Generic Drug Price Scandal: Too Bitter a Pill for the Drug Price Competition and Patent Term Restoration Act to Swallow, 75 Notre Dame L. Rev. 309 (1999).
3. FDA link (FDA To Conduct Inspections Focusing on 21 CFR 11 (Part 11) requirements relating to human drugs) –http://www.fda.gov/AboutFDA/CentersOffices/OfficeofMedicalProductsandTobacco/CDER/ucm204012.htm
A common myth is the statement that data integrity is a new requirement of cGMP. In 2003 ‘Part 11, Electronic Records; Electronic Signatures — Scope and Application’ was published followed by an announcement in 2010 of the FDA, stating that the agency will be conducting inspections focusing on 21 CFR Part 11 requirements3. This announcement has been followed accordingly with data integrity now being a primary inspection focus and with the presence of highly qualified inspectors trained specifically in data integrity.
Today, the regulatory literature has been expanded significantly since the emergence of 21 CFR part 11 giving further guidance in authorities’ interpretation in cGMP requirements and their own guidelines. A list of relevant available literature is provided below:
- US FDA 21 CFR Part 11
- EudraLex, Volume 4 Good Manufacturing Practice (Annex 11)
- MHRA GMP Data Integrity Definitions and Guidance for Industry March 2015
- FDA Guidance for Industry Data Integrity and Compliance with cGMP April 2016 (draft)
- WHO Guidance on Good Data and Record Management Practices September 2015 (draft)
Spectrum of Data Integrity Issues
When studying warning letters given by regulatory authorities it is evident that the term ‘data integrity’ covers a wide range of issues. These issues can vary in degree of severity in a spectrum as shown in Figure 1:

Figure 1 – Spectrum of data integrity issues pending from minor bad practices to full-blown falsification scandals
Examples of actual warning letters containing these categories are given below:

Table 1 – Examples of data integrity issues referencing actual warning letters
Working with Data Integrity in Practice – ALK’s process for auditing data
The objective of performing an audit of data during development is to provide an assessment of the data quality based on a statistically sound data audit sampling plan, as well as a data audit sampling strategy. The amount of source documentation and data generated prior to regulatory approvals are extensive and the data generated has (hopefully!) already been verified prior to the reporting of results. Therefore, the most meaningful way of auditing the data is by developing a solid, statistically sound sampling plan. The scope of ALK’s data auditing process is summarized in Figure 2:

Figure 2 – Scope of Audit of Data Review performed by QA
The verification and execution of audit is performed by QA and with involvement of relevant areas where source documentation and data have been generated. Furthermore, a sampling plan has been designed taking into consideration parameters such as:
- AQL (Acceptable Quality Level): defined as the level of document quality (percent defective) the sampling plan routinely accepts
- RQL (Reject Quality Level): defined as the level of document quality (percent defective) the sampling routinely rejects
- Accept number (a): Defective count that, if exceeded, will subject the verified document to appropriate corrective actions
- Lot size of population (N): in this context the total number of data points in a document
- Sample size (n): Total number of data points sampled from a document
The set values that are to be used for AQL, RQL, a, N, and n must be determined by the individual company. Our experience at ALK has shown that it is mandatory to include a skilled statistician in these considerations. Furthermore, we have implemented error categories, such as Critical, Major and Minor for detected investigational findings (data errors), while also establishing gradual AQL and RQL levels for the different error categories based on criticality.
Data Integrity is for the patients
Ultimately, data integrity compliance is for the sake of the patients. Data integrity compliance and thereby trustworthy, accurate and complete data is necessary for assuring medicines’ and medical devices’ safety, efficacy and quality. The challenges faced when determining which statistical parameters and parameter levels to be used are challenging as well as exciting.
Data integrity is the maintenance of, and the assurance of the accuracy and consistency of, data over its entire life-cycle,[1] and is a critical aspect to the design, implementation and usage of any system which stores, processes, or retrieves data. The term data integrity is broad in scope and may have widely different meanings depending on the specific context – even under the same general umbrella of computing. This article provides only a broad overview of some of the different types and concerns of data integrity.
Data integrity is the opposite of data corruption, which is a form of data loss. The overall intent of any data integrity technique is the same: ensure data is recorded exactly as intended (such as a database correctly rejecting mutually exclusive possibilities,) and upon later retrieval, ensure the data is the same as it was when it was originally recorded. In short, data integrity aims to prevent unintentional changes to information. Data integrity is not to be confused with data security, the discipline of protecting data from unauthorized parties.
Any unintended changes to data as the result of a storage, retrieval or processing operation, including malicious intent, unexpected hardware failure, and human error, is failure of data integrity. If the changes are the result of unauthorized access, it may also be a failure of data security. Depending on the data involved this could manifest itself as benign as a single pixel in an image appearing a different color than was originally recorded, to the loss of vacation pictures or a business-critical database, to even catastrophic loss of human life in a life-critical system.
Integrity types
Physical integrity
Physical integrity deals with challenges associated with correctly storing and fetching the data itself. Challenges with physical integrity may include electromechanical faults, design flaws, material fatigue, corrosion, power outages, natural disasters, acts of war and terrorism, and other special environmental hazards such as ionizing radiation, extreme temperatures, pressures and g-forces. Ensuring physical integrity includes methods such as redundant hardware, an uninterruptible power supply, certain types of RAID arrays,radiation hardened chips, error-correcting memory, use of a clustered file system, using file systems that employ block level checksums such as ZFS, storage arrays that compute parity calculations such as exclusive or or use a cryptographic hash function and even having a watchdog timer on critical subsystems.
Physical integrity often makes extensive use of error detecting algorithms known as error-correcting codes. Human-induced data integrity errors are often detected through the use of simpler checks and algorithms, such as the Damm algorithm or Luhn algorithm. These are used to maintain data integrity after manual transcription from one computer system to another by a human intermediary (e.g. credit card or bank routing numbers). Computer-induced transcription errors can be detected through hash functions.
In production systems these techniques are used together to ensure various degrees of data integrity. For example, a computer file system may be configured on a fault-tolerant RAID array, but might not provide block-level checksums to detect and prevent silent data corruption. As another example, a database management system might be compliant with the ACID properties, but the RAID controller or hard disk drive’s internal write cache might not be.
Logical integrity
This type of integrity is concerned with the correctness or rationality of a piece of data, given a particular context. This includes topics such as referential integrity and entity integrity in a relational database or correctly ignoring impossible sensor data in robotic systems. These concerns involve ensuring that the data “makes sense” given its environment. Challenges include software bugs, design flaws, and human errors. Common methods of ensuring logical integrity include things such as a check constraints,foreign key constraints, program assertions, and other run-time sanity checks.
Both physical and logical integrity often share many common challenges such as human errors and design flaws, and both must appropriately deal with concurrent requests to record and retrieve data, the latter of which is entirely a subject on its own.
Databases
Data integrity contains guidelines for data retention, specifying or guaranteeing the length of time data can be retained in a particular database. It specifies what can be done with data values when their validity or usefulness expires. In order to achieve data integrity, these rules are consistently and routinely applied to all data entering the system, and any relaxation of enforcement could cause errors in the data. Implementing checks on the data as close as possible to the source of input (such as human data entry), causes less erroneous data to enter the system. Strict enforcement of data integrity rules causes the error rates to be lower, resulting in time saved troubleshooting and tracing erroneous data and the errors it causes algorithms.
Data integrity also includes rules defining the relations a piece of data can have, to other pieces of data, such as a Customer record being allowed to link to purchased Products, but not to unrelated data such as Corporate Assets. Data integrity often includes checks and correction for invalid data, based on a fixed schema or a predefined set of rules. An example being textual data entered where a date-time value is required. Rules for data derivation are also applicable, specifying how a data value is derived based on algorithm, contributors and conditions. It also specifies the conditions on how the data value could be re-derived.
Types of integrity constraints
Data integrity is normally enforced in a database system by a series of integrity constraints or rules. Three types of integrity constraints are an inherent part of the relational data model: entity integrity, referential integrity and domain integrity:
- Entity integrity concerns the concept of a primary key. Entity integrity is an integrity rule which states that every table must have a primary key and that the column or columns chosen to be the primary key should be unique and not null.
- Referential integrity concerns the concept of a foreign key. The referential integrity rule states that any foreign-key value can only be in one of two states. The usual state of affairs is that the foreign-key value refers to a primary key value of some table in the database. Occasionally, and this will depend on the rules of the data owner, a foreign-key value can be null. In this case we are explicitly saying that either there is no relationship between the objects represented in the database or that this relationship is unknown.
- Domain integrity specifies that all columns in a relational database must be declared upon a defined domain. The primary unit of data in the relational data model is the data item. Such data items are said to be non-decomposable or atomic. A domain is a set of values of the same type. Domains are therefore pools of values from which actual values appearing in the columns of a table are drawn.
- User-defined integrity refers to a set of rules specified by a user, which do not belong to the entity, domain and referential integrity categories.
If a database supports these features, it is the responsibility of the database to ensure data integrity as well as the consistency model for the data storage and retrieval. If a database does not support these features it is the responsibility of the applications to ensure data integrity while the database supports the consistency model for the data storage and retrieval.
Having a single, well-controlled, and well-defined data-integrity system increases
- stability (one centralized system performs all data integrity operations)
- performance (all data integrity operations are performed in the same tier as the consistency model)
- re-usability (all applications benefit from a single centralized data integrity system)
- maintainability (one centralized system for all data integrity administration).
As of 2012, since all modern databases support these features (see Comparison of relational database management systems), it has become the de facto responsibility of the database to ensure data integrity. Out-dated and legacy systems that use file systems (text, spreadsheets, ISAM, flat files, etc.) for their consistency model lack any[citation needed]kind of data-integrity model. This requires organizations to invest a large amount of time, money and personnel in building data-integrity systems on a per-application basis that needlessly duplicate the existing data integrity systems found in modern databases. Many companies, and indeed many database systems themselves, offer products and services to migrate out-dated and legacy systems to modern databases to provide these data-integrity features. This offers organizations substantial savings in time, money and resources because they do not have to develop per-application data-integrity systems that must be refactored each time the business requirements change.
Examples
An example of a data-integrity mechanism is the parent-and-child relationship of related records. If a parent record owns one or more related child records all of the referential integrity processes are handled by the database itself, which automatically ensures the accuracy and integrity of the data so that no child record can exist without a parent (also called being orphaned) and that no parent loses their child records. It also ensures that no parent record can be deleted while the parent record owns any child records. All of this is handled at the database level and does not require coding integrity checks into each applications.
File systems
Various research results show that neither widespread filesystems (including UFS, Ext, XFS, JFS and NTFS) nor hardware RAID solutions provide sufficient protection against data integrity problems.[2][3][4][5][6]
Some filesystems (including Btrfs and ZFS) provide internal data and metadata checksumming, what is used for detecting silent data corruption and improving data integrity. If a corruption is detected that way and internal RAID mechanisms provided by those filesystems are also used, such filesystems can additionally reconstruct corrupted data in a transparent way.[7] This approach allows improved data integrity protection covering the entire data paths, which is usually known as end-to-end data protection.[8]
Data storage
Apart from data in databases, standards exist to address the integrity of data on storage devices.[9]
See also
References
- Jump up^ Boritz, J. “IS Practitioners’ Views on Core Concepts of Information Integrity”.International Journal of Accounting Information Systems. Elsevier. Retrieved 12 August2011.
- Jump up^ Vijayan Prabhakaran (2006). “IRON FILE SYSTEMS” (PDF). Doctor of Philosophy in Computer Sciences. University of Wisconsin-Madison. Retrieved 9 June 2012.
- Jump up^ “Parity Lost and Parity Regained”.
- Jump up^ “An Analysis of Data Corruption in the Storage Stack” (PDF).
- Jump up^ “Impact of Disk Corruption on Open-Source DBMS” (PDF).
- Jump up^ “Baarf.com”. Baarf.com. Retrieved November 4, 2011.
- Jump up^ Bierman, Margaret; Grimmer, Lenz (August 2012). “How I Use the Advanced Capabilities of Btrfs”. Retrieved 2014-01-02.
- Jump up^ Yupu Zhang, Abhishek Rajimwale, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau.“End-to-end Data Integrity for File Systems: A ZFS Case Study” (PDF). Computer Sciences Department, University of Wisconsin. Retrieved 2014-01-02.
- Jump up^ Smith, Hubbert (2012). Data Center Storage: Cost-Effective Strategies, Implementation, and Management. CRC Press. ISBN 9781466507814. Retrieved 2012-11-15.
T10-DIF (data integrity field), also known as T10-PI (protection information model), is a data-integrity extension to the existing information packets that spans servers and storage systems and disk drives.
Further reading
 This article incorporates public domain material from the General Services Administration document “Federal Standard 1037C” (in support of MIL-STD-188).
This article incorporates public domain material from the General Services Administration document “Federal Standard 1037C” (in support of MIL-STD-188).- Xiaoyun Wang; Hongbo Yu (2005). “How to Break MD5 and Other Hash Functions” (PDF). EUROCRYPT. ISBN 3-540-25910-4.
Data Integrity Key to GMP Compliance
It may seem to some members of the biopharmaceutical manufacturing community that incomplete records and faulty documentation are much less serious than contaminated facilities and unsafe products. But to FDA officials, data that are not valid and trustworthy is a sign that an entire operation or facility is out of control and cannot assure the quality of its medicines. As FDA struggles to devise a more targeted, risk-based approach to overseeing the vast, global network of pharmaceutical ingredient suppliers and manufacturers, agency officials find themselves hampered by unreliable industry information.
New mandates to attain parity in inspection of foreign and domestic facilities further complicates the picture by expanding FDA oversight to many firms less familiar with US standards. As erroneous and fraudulent records continue to surface during plant inspections and in submissions filed with the agency–despite years of warning letters criticizing such infractions–FDA leaders are ramping up the rhetoric to compel manufacturers to clean up data operations.
A lack of data integrity often is “just fraud,” says Howard Sklamberg, FDA deputy commissioner for global regulatory operations and policy. FDA relies on company information documenting adherence to cGMPs, he explained at a July conference on “Understanding cGMPs” sponsored by the Food and Drug Law Institute (FDLI). Yet almost all recent warning letters cite evidence of altered and falsified records. If data are “knowingly incorrect, we take that very seriously,” Sklamberg stated, expressing dismay that some manufacturers still fail to remedy record-keeping problems despite repeated warnings from the agency.
Sklamberg anticipates more prosecution of data integrity issues to deter violative behavior. FDA aims to make biopharmaceutical companies that hide manufacturing data discrepancies and that display a lack of integrity in regulatory programs and policies “increasingly uncomfortable,” said Thomas Cosgrove, acting director of the Office of Manufacturing and Project Quality (OMPQ) in the Office of Compliance (OC), Center for Drug Evaluation and Research (CDER). In addition to warning letters, inaccurate and unreliable data can expose a firm to product seizures, import alerts, and broader injunctions, he explained at the FDLI conference.
The most serious data breaches are handled by FDA’s Office of Criminal Investigation (OCI) in the Office of Regulatory Affairs (ORA), which manages the agency’s 1800 investigators and some 200 OCI special agents. FDA will perform extensive audits and impose penalties, which can be more expensive to a firm than “getting it right the first time,” Cosgrove observed.
High quality data also are “a very big issue” related to medical product imports, which are rising exponentially, commented Douglas Stearn, director of enforcement and import policy at ORA. He noted that dealing with poor data slows down FDA operations and thus imposes a visible cost on the agency. “We’re looking at that very closely,” he said.
Not just India
Data integrity issues have always existed, but now FDA is doing more to uncover the evidence of such problems, acknowledged Carmelo Rosa, director of OMPQ’s Division of International Drug Quality. FDA is training investigators to better detect signs of data problems and is looking more closely at international facilities for signs of altered and doctored records.
But it’s “not only India” that is experiencing these problems, said Rosa; data integrity issues have surfaced in all regions. A July 2014 warning letter, for example, cited Italian API producer Trifarma S.p.A. for deleting key test data and failing to establish systems to identify how and when changes are made in manufacturing records. Tianjin Zhogan Pharmaceutical Co. in China received a warning letter in June citing inadequate records of manufacturing and cleaning operations (1).
Certainly, many of the most egregious data integrity transgressions have surfaced at Indian API facilities. From mid-2013 to mid-2014, seven Indian manufacturers received warning letters referencing the integrity of their records, procedures, and interactions with FDA investigators, according to a report by International Pharmaceutical Quality (IPQ) (2). Wockhardt Ltd. was cited in July 2013 for multiple GMP violations, including efforts to cover up faulty and incomplete anti-microbial studies, stability protocols, and batch testing. Ranbaxy Laboratories recently was hit by an import ban on two facilities in India, culminating in a series of enforcement actions following the discovery of widespread falsification of data and test results more than five years ago.
Drug makers should not look to contract manufacturers to reduce their responsibility for data accuracy and reliability, Rosa noted at the July CMC Workshop on “Effective Management of Contract Organizations” sponsored by CASSS. Some biopharma companies regard contract testing and production operations as one way to alleviate their involvement in inspections and dealings with regulatory authorities. But Rosa emphasized that the licensed manufacturer remains responsible for products meeting all quality standards and noted that FDA and other authorities are looking closely at all facilities, including CMOs.
To document that manufacturing processes comply with GMPs, biopharmaceutical companies are required to retain complete and accurate production information and to make that available to FDA inspectors, explained OMPQ branch chief Alicia Mozzachio at the FDLI conference. She observed, however, that agency investigators continue to uncover multiple data integrity issues: failure to record activities contemporaneously; document back-dating; copying existing data as new information; re-running samples to obtain better results; and fabricating or discarding data. Parexel Vice-President David Elder cited recent FDA warnings letters that refer to “unofficial testing” and “trial” analysis of samples until the data come out right and evidence that records are signed by company personnel absent from work that day.
Rosa added that field inspectors encounter employees who admit to falsification of records and that certain operations were not performed as recorded. When FDA uncovers such discrepancies at one company site, Mozzachio said, that becomes a “red flag” for FDA to look closely at records and practices at a firm’s other manufacturing facilities.
Key indicators
Data integrity matters because properly recorded information is the basis for manufacturers to assure product identity, strength, purity, and safety, Elder pointed out. Frances Zipp, president of Lachman Consultants, observed that data integrity has become a main focus of FDA inspections, as agency audits aim to determine how well company management monitors sites and ensures the “rigor and effectiveness” of global compliance. Evidence of misrepresented data or problems with batch records found during a preapproval inspection is a prime factor leading to delays in market approval.
Inaccurate manufacturing data, moreover, threatens to undermine FDA efforts to streamline regulatory processes, which is of particular concern to agency leaders. Cosgrove explained that FDA is working hard to establish systems for targeting inspections to more high-risk products and operations. The aim is to focus agency resources on the greatest sources of risk to patients, while also reducing oversight of firms with “robust quality systems,” which, he said, then may benefit from “less interference from FDA.”
But for such a strategy to work, the data that FDA receives “must be real,” he stated. Cosgrove voiced particular dismay over company executives and attorneys who “shade the facts” and that resulting integrity issues can “have consequences.”
References
1. Warning Letter to Tianjin Zhogan Pharmaceutical Co., WL: 320-14-09 (June 10, 2014),
2. International Pharmaceutical Quality, Apr. 28, 2014. PT


NEXT……..

NEXT……..

NEXT……..

NEXT……..

NEXT……..

NEXT……..

NEXT……..

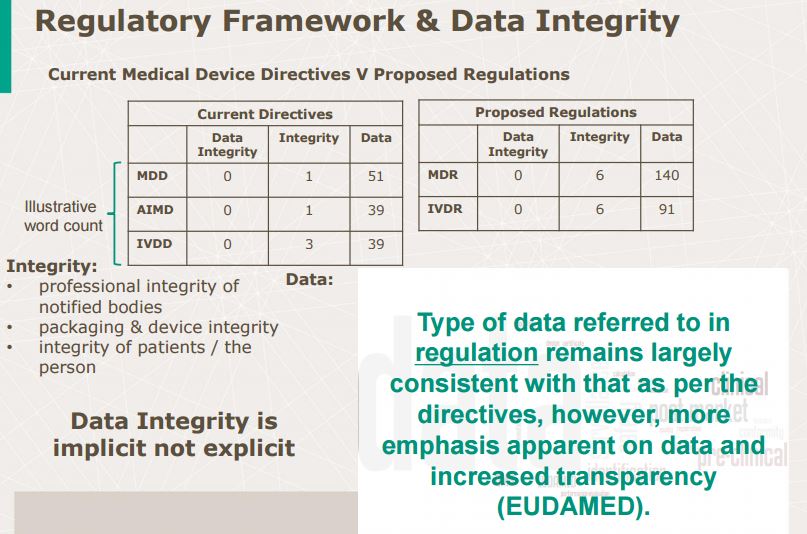
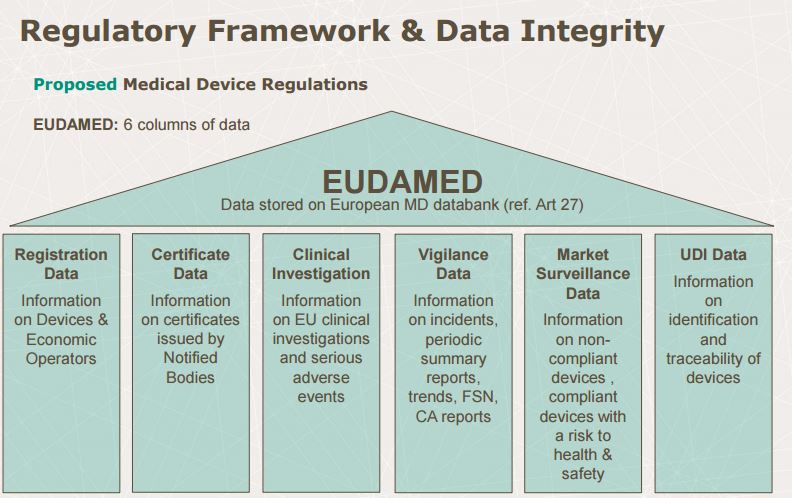





The presentation will load below
/////////////
42,018 total views, 1 views today
